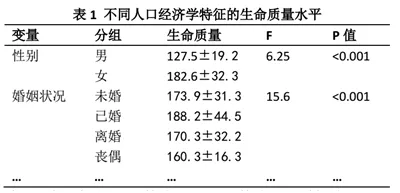
前段时间,有个学生就就论文修回中专家意见咨询,专家对下面的表格两组均数比较应该采用t检验而不是方差分析(F检验)。专家认为,男性和女性的生命质量比较应该用t检验,而不是F检验。真应该这样子的吗?
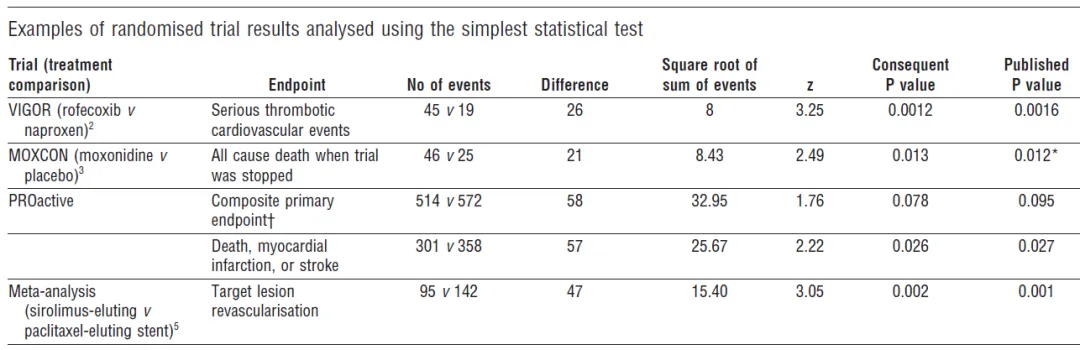
统计学最常见的统计学检验就是两组数据之间的差异性方法。比如两组均数、两组率、两组偏态分布数据的比较等。常见的方法有t检验、卡方检验、z检验、LogRank检验。
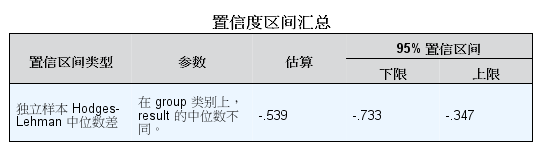
我今天来解释解释,大样本非常明显的偏态数据能不能进行t检验和方差分析。先来说说,中心极限理论。。。。它的意思是无论原始数据如何分布,只要样本量大于30以上,样本均数的分布将呈现正态分布!

虽然临床试验项目项目难实施,但临床、中医、护理很多人还是发起了IIT项目,即研究者发起的临床项目。我也参加了很多的评审,发现结局指标的设置真的是要给大问题,要么主次不分,要么形式不定,要么时间定义不不清晰。

现在对医学研究缺失数据填补的问题,很多人都有了一定的思考,有缺失,还是要填补,无论是临床试验、调查研究,无论是前瞻性还是回顾性。
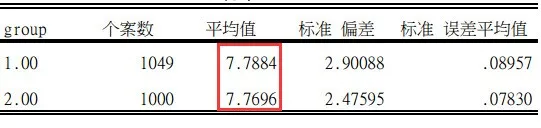
流行病学调查中,许多指标比如量表总得分、个体生理、生化指标等呈现偏态分布。面对这种情况,我们如何处理呢?一组数据,特别是正态性检验P值小于0.05的资料,能否使用t检验或者F检验一直有着争议。

2025年,我们将收集大家最关心的问题,由郑老师以及团队统计师们进行解答,并写成统计小食推文分享,诸位不妨关注我们的系列推文。
-cnjk.png)
今天是我们统计小食系列文章第二篇:两组数据基线特征差异性特别大,倾向得分匹配做出来结果不好怎么办?
.png)
今天是我们统计小食系列文章第三篇:样本量足够大,理论上正态分布,旦正态性检验P值小于0.001可以用t检验吗?这个话题真的很传统、又很重要、往往大家又搞不清。
-sxng.png)
有人问我,“郑老师,临床试验做起来太困难,导致样本量太小,可以做非随机对照研究吗?"好像可以,好像又不可以。郑老师给大家解答一下,这是统计小食系列第四篇!
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

