
之前有学员提问,"我想做一个预测模型,预测因子可以用轨迹模型的分组吗?"就连我最看好的一个研究生,也搞不清楚这个问题。今天的统计小食,陈老师来讲讲!
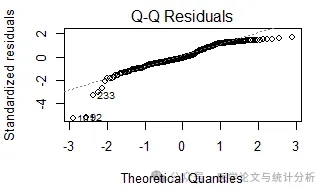
今天,我们统计小食第五篇的主题是:多元线性回归要求因变量一定要符合正态分布吗?不符合正态分布怎么办?
有学员问,"老师,构建诊断预测模型,如果用前瞻性队列的数据,随访的时间是不是要更长呢?其实这个问题,陈老师认为不应该从这个角度去思考,因为影响随访时间的因素实在是太多了。今天陈老师来简单讲一讲这个问题。
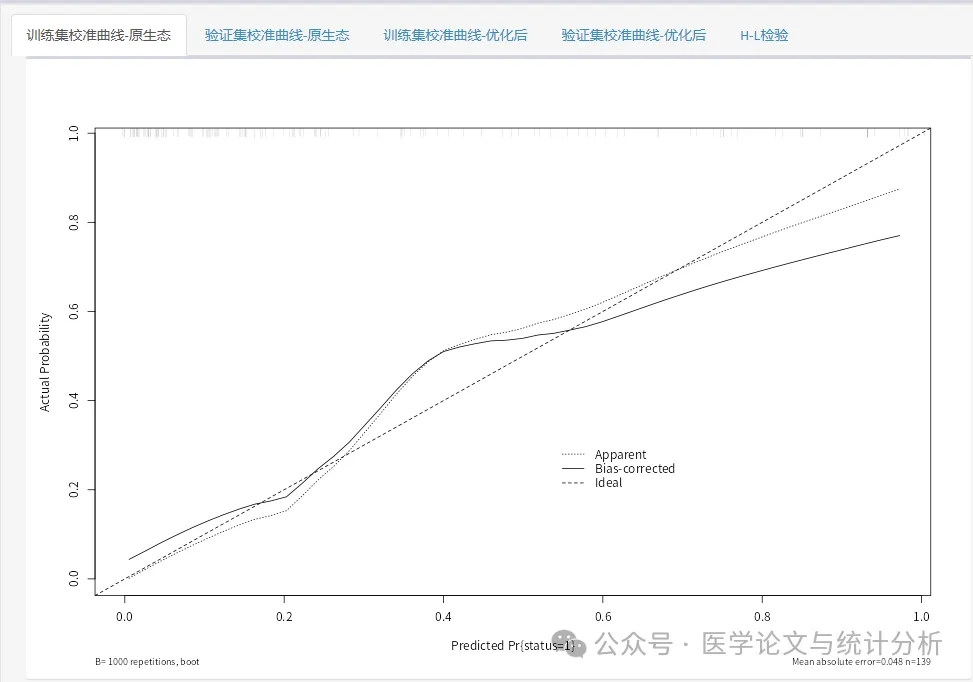
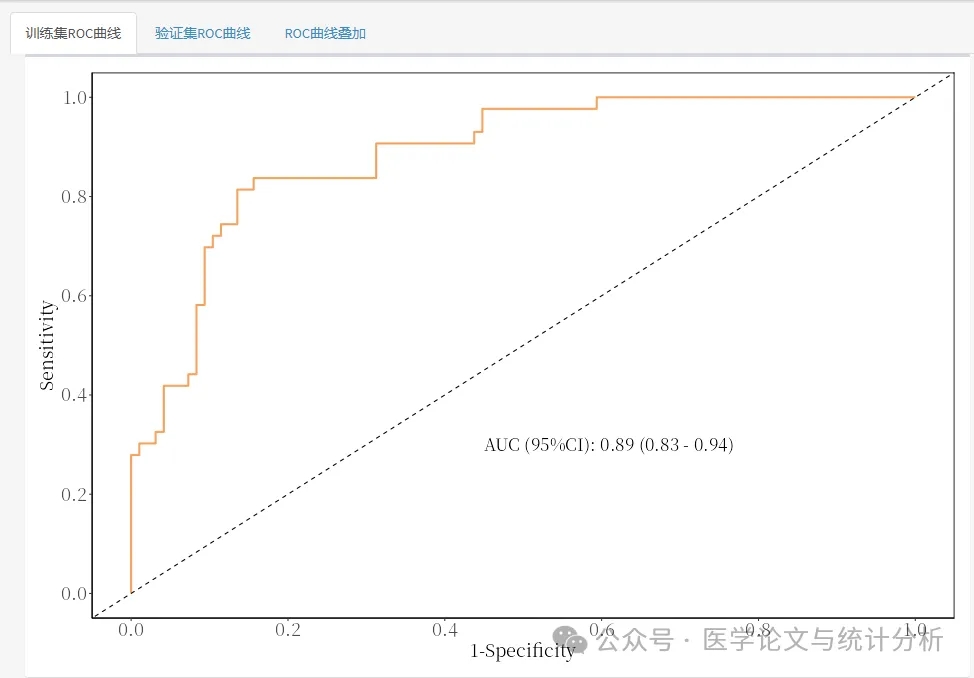
“不同类型的预测模型,是不是要用不同的方法评估模型性能?这个问题,相信很多预测模型初学者都问过。不同类型的数据该用什么分析方法,对于模型性能的评价指标又有什么差别,今天陈老师就来给大家讲一讲。
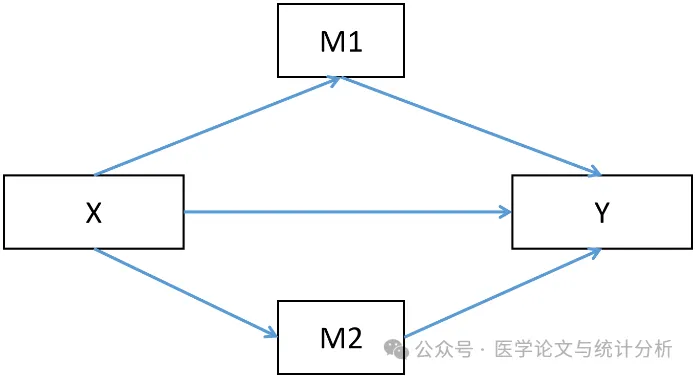
上次有学员问,“我该怎么在回归中考虑中介变量?直接把它放到logistic回归或者lasso回归筛选变量中校正行不行?今天是我们统计小食第八篇,陈老师来给大家好好讲一下这个问题。
.png)
今天是统计小食系列第九篇文章,陈老师想和大家聊聊近几年比较热门的网状Meta。
.jpg)
我知道很多人在纠结,Cox回归预测模型中计算总的C指数,和Bootstrap法计算每年的C指数,这两者有什么区别?今天陈老师就给大家简单讲讲两者如何区分。
-souf.jpg)

前段时间有一个学生,拿着自己的分析数据来问我,"郑老师,我的中介效应分析结果和别人不一样,效应量是负的,这是正常的吗?"

今天我们统计小食第十二篇,今天郑老师解答的问题是:多组样本的临床试验,如何计算样本量?
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

