
2026年4月29日,顶级医学期刊NEJM发布了一则撤稿声明。而就在11天前,这篇题为“Bronchial Casts from Inhalation of Forest-Fire Smoke”的报告才刚刚上线。

很多父母都希望通过母乳喂养给孩子一个更好的起点,但关于母乳喂养能否提升孩子长期认知能力的研究结论一直并不统一。 这种差异往往源于不同背景下家庭社会经济地位的复杂干扰,那么在中国青少年群体中,这两者之间到底存在怎样的联系? 今天分享一篇浙江大学的学者发表在《JAMA Network Open》(医学一区top,IF=6.9)的研究论文,研究团队使用中国家庭追踪调查(CFPS)的数据,旨在探究中国青少年母乳喂养持续时间和认知结果之间的关系。
近期,中山大学的学者在《Lancet Digital Health》(医学一区top,IF=24.1)上发表了一项研究,系统探讨了LLM能否帮助年轻研究者生成足够新颖且有用的临床科研思路。
今天分享一篇清华大学学者发表在《Scientific Data》(综合二区,IF=6.9)的研究文章,研究团队开发了一个名为WorldMove的全球人类移动数据集,完全免费开源,目前已覆盖179个国家和六大洲的超过1600个城市。

Logistic回归,统计分析的万金油!但有些情况,不再适合用logistic回归了,更推荐修正泊松回归。 诸位有没有这样的情况,只要一项医学研究,结局是二分类数据,第一下想到的肯定是logistic回归。确实,在现况调查、在病例对照研究、在队列研究、在随机对照研究都可以使用。
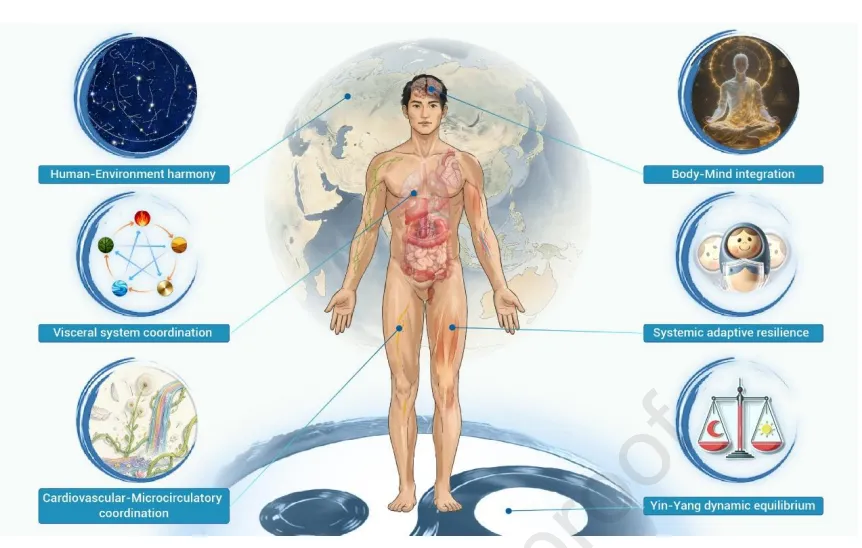
近期,福建中医药大学林尧教授与褚剑锋教授团队,联合南京中医药大学程海波教授团队、葛立林在国际顶尖期刊《The Innovation》(综合性期刊一区,IF=25.7)在线发表了一篇文章,题为“Hallmarks of health: A Chinese medicine perspective”。

没有科研经费、没有WiFi、没有医生团队、甚至连智能手机都不用——你猜这样的研究能发到哪里? 《Circulation》,影响因子 38.6。

今天分享的两篇文章出自同一团队之手,用了几乎完全一样的选题和分析套路,不仅回答了上述问题,更在短时间内双发一区Top刊!这不得赶紧学起来?

广义线性模型(generalized linear model, GLM)是一种灵活的统计模型框架。 它扩展了传统线性模型,将因变量分布从正态扩展到指数族分布,以适应各种不同的数据分布和类型。 包括二项分布、泊松分布、伽马分布、逆高斯分布等,同一套理论框架可以处理连续、分类或离散型等多种类型的数据。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

