
今天我们分享一篇发表在《Scientific Reports》的研究论文,研究团队旨在应用双重机器学习(DML)框架,探讨了司库奇尤单抗从150mg升至300mg对疾病活动度和生活质量的个体化因果效应。

今天分享一篇基于自动机器学习(AutoML)与双重机器学习(DML)相结合的研究,作者系统评估了中国67个城市饮用水中ARGs的驱动因素,并实现了从“关联挖掘”到“因果验证”的完整分析框架。
由于可以使用大量数据进行训练,还能整合基因图谱、影像、脑电图、生理数据等多种数据源,因此机器学习(ML)算法特别适合个体化医疗。 今天分享一篇基于集成机器学习,结合从医疗记录中提取的多模态临床和放射学特征,开发和验证一种非侵入性、临床适用的预测模型的研究论文。

胃癌前病变(PLGC)是胃癌进展的关键阶段,及时干预可显著降低死亡率。 然而,当前筛查策略主要依赖内窥镜检查,不仅费用高、侵入性,在资源有限地区更是难以普及。
-RFty.png)
在该项研究中,研究团队使用了去身份化电子健康记录(EHR)数据,纳入老年患者。 本研究旨在基于8种机器学习法和SHAP法,构建可解释机器学习预测模型,以评估风险因素并预测老年心合并高血压患者的住院死亡率。 √缺失数据的处理 研究中所有变量的缺失数据比例均保持在30%以下,使用K-最近邻(KNN)分类算法对缺失数据进行处理。 √变量筛选 使用LASSO法在44个变量中筛选出9个最佳预测因子,包括年龄、住院时间(LOS)、中性粒细胞(Neu)、尿素、Cl、活化部分凝血活酶时间(APTT)、白细胞(LEU)、白蛋白和HDL胆固醇。
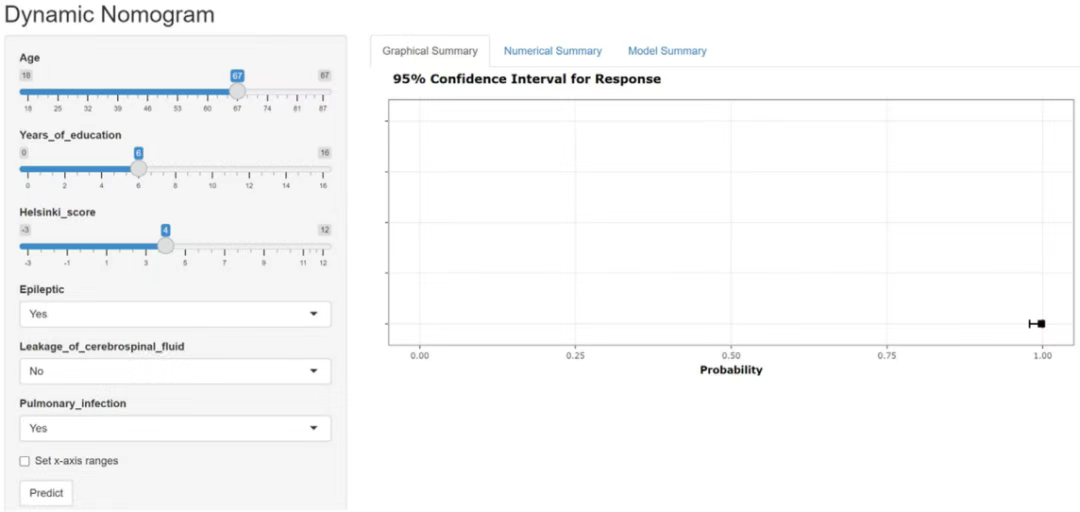
【欢迎阅读浙中大郑老师撰写的统计科普文】 预测模型文章中,我们一般用10倍EPV原则计算样本量,这也是目前公认的方法,但很少有学者会在文章中详细地解释。
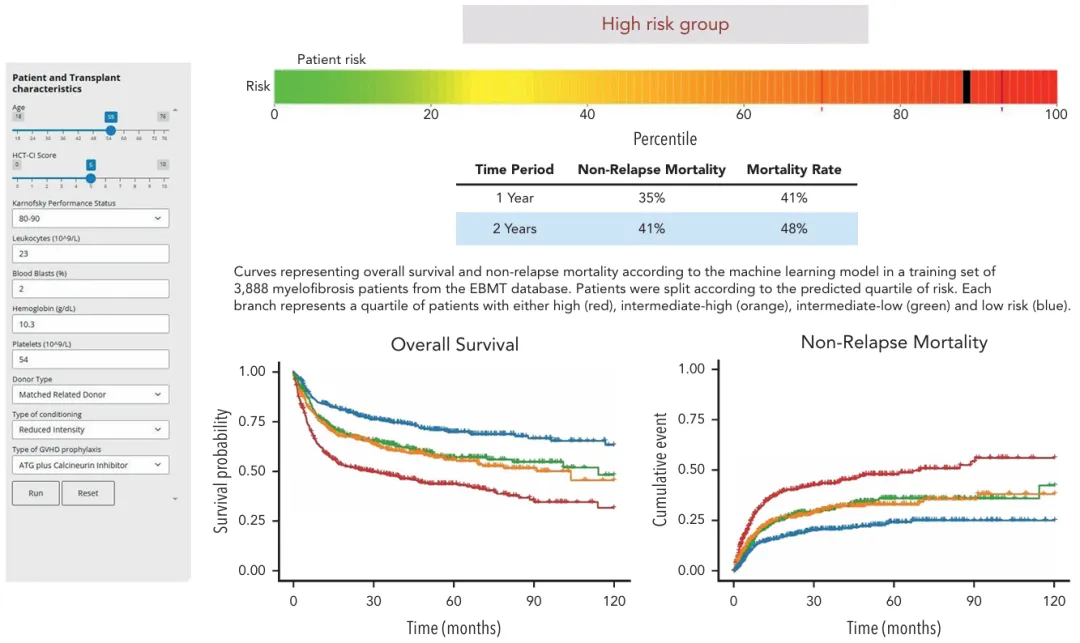
医学一区,IF=23.1的杂志《Blood》刊登了一篇机器学习预测模型的研究,题为:“Use of machine learning techniques to predict poor survival after hematopoietic cell transplantation for my
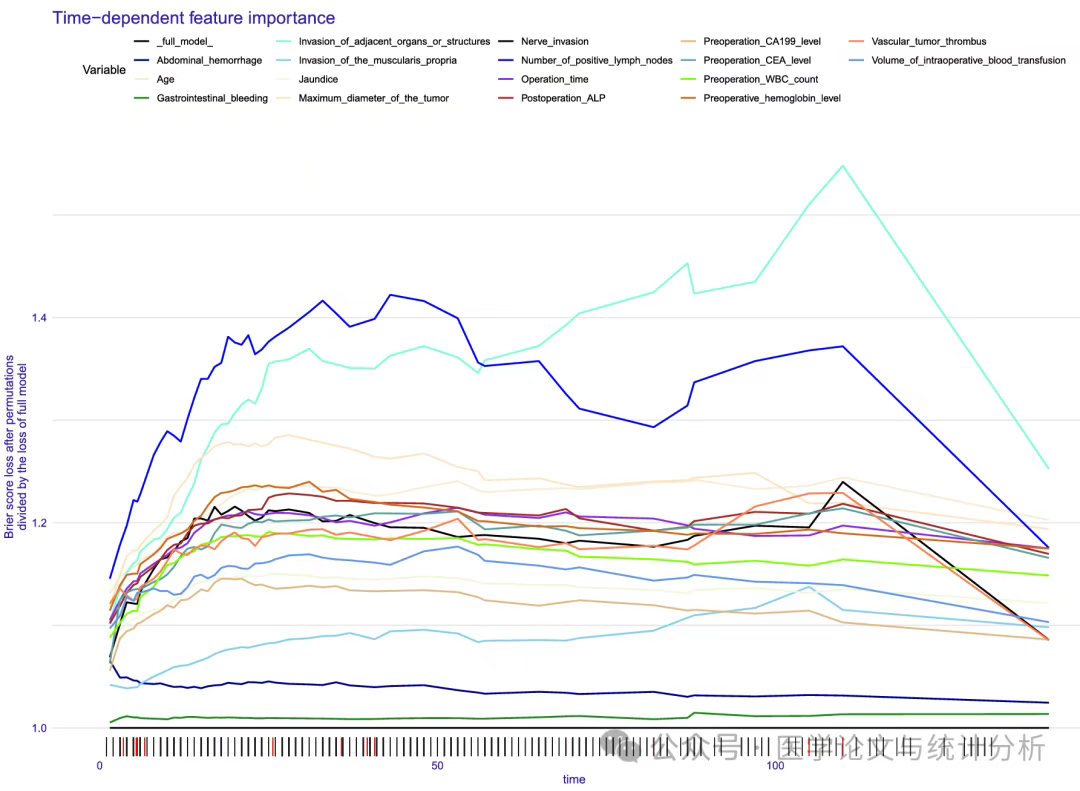
老郑看到一篇文章,机器学习建模建了100个,挺有意思的,是实力?还是内卷?我们一起看看! 这篇文章是中国学者发表在中科院一区,影响因子7.0的杂志
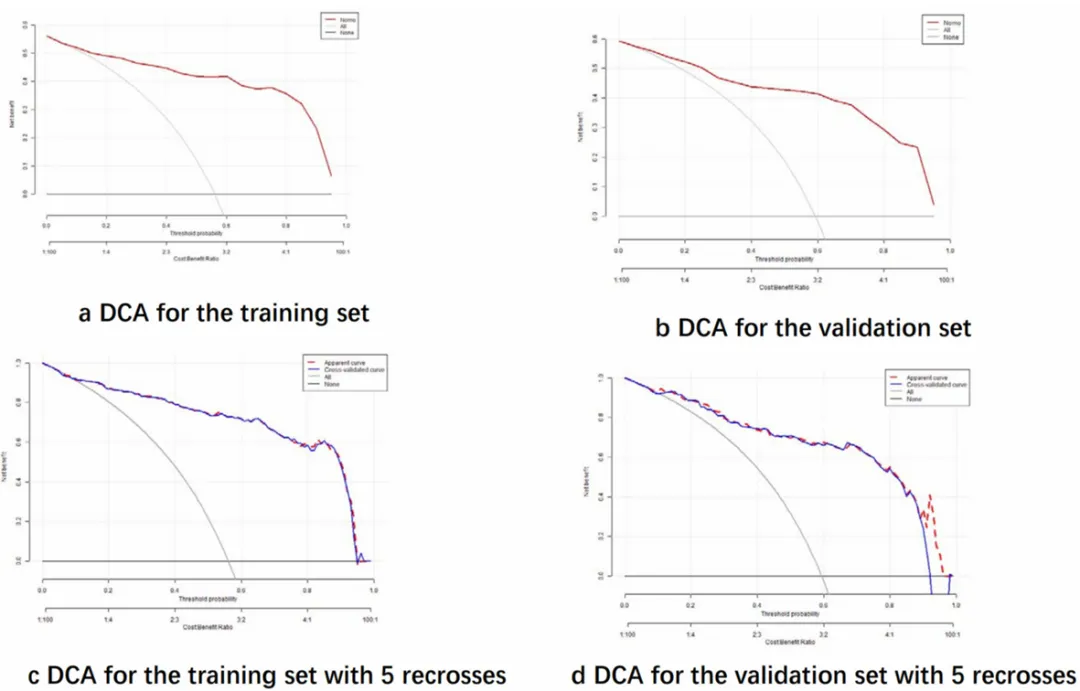
现如今,在预测模型领域中,传统回归模型和机器学习模型应用已经十分广泛,各有优缺点。 在机器学习构建预测模型文章中,也经常出现Logistic回归。 那为什么郑老师说,如果机器学习预测模型差别不大,首推传统logistic回归呢? 借上海交通大学学者2025年5月发表的一篇文章,一起来
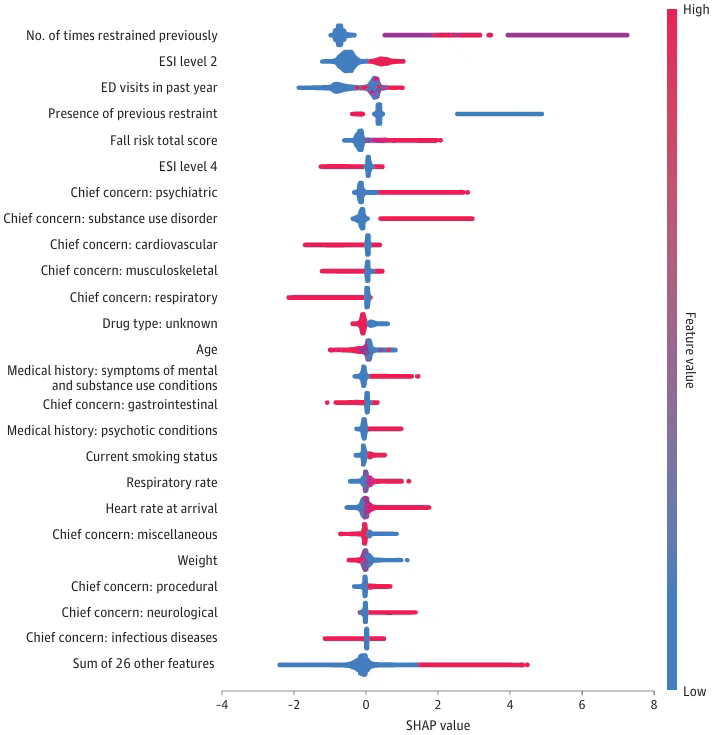
2025年5月7日,JAMA子刊《JAMA Network Open》(医学一区top,IF=10.5
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

