-ggff.png)
.png)


.png)
.png)
.png)


.png)
-fzxo.png)
-mlpy.png)


.png)
-roIP.png)
.png)


.png)
.png)

-gowy.png)
.png)
.png)

在现实中,疾病的发生和发展通常是由复杂的、相互依赖的多个变量相互作用的结果。病人往往有多种共病,指标都是动态变化的。 比如我们要如何理解血糖、血压、胆固醇这三者在一个糖尿病患者群体中5年内的变化关系?这些指标之间是如何相互关联、共同演变的?

各位好!欢迎使用郑老师团队风暴统计平台,如需开通高级版使用权限,请按要求提供ID号(复制版)! 请注意:高级版权限,统一于工作日上午 11:00、下午 17:00由助教开通,周末及非工作时段暂不开通,请大家及时提供ID号,感谢配合!

由于可以使用大量数据进行训练,还能整合基因图谱、影像、脑电图、生理数据等多种数据源,因此机器学习(ML)算法特别适合个体化医疗。 今天分享一篇基于集成机器学习,结合从医疗记录中提取的多模态临床和放射学特征,开发和验证一种非侵入性、临床适用的预测模型的研究论文。
近期,中国医学科学院阜外医院李静研究员领衔开展的多中心临床试验成果,发表于心脏病顶刊《Journal of the American College of Cardiology》(医学一区,IF=22.3)。 该研究首次证实,中国传统健身气功八段锦(Baduanjin)可有效降低正常高值血压人群的血压,且即使在无干预监测的情况下,降压效果仍可维持长达1 年,为传统功法应用于该人群血压管理提供了高质量循证证据。
各位好!欢迎使用郑老师团队风暴统计平台,如需开通高级版使用权限,请按要求提供ID号(复制版)! 请注意:高级版权限,统一于工作日上午 11:00、下午 17:00由助教开通,周末及非工作时段暂不开通,请大家及时提供ID号,感谢配合!
近期,中国医学科学院阜外医院李静研究员领衔开展的多中心临床试验成果,发表于心脏病顶刊《Journal of the American College of Cardiology》(医学一区,IF=22.3)。 该研究首次证实,中国传统健身气功八段锦(Baduanjin)可有效降低正常高值血压人群的血压,且即使在无干预监测的情况下,降压效果仍可维持长达1 年,为传统功法应用于该人群血压管理提供了高质量循证证据。

启动一项新的临床试验前,你会花多少时间回顾已有的研究? 这个问题看似很基础,现实中却常被忽略。有的研究者可能觉得时间紧任务重,凭经验也就够了;也有的研究者则是不知道从哪查起。

2026年3月4日,复旦大学附属中山医院樊嘉院士、周俭院士和施国明教授团队在医学顶刊《NEJM》(医学一区Top,IF=78.5)发表最新临床试验研究成果。
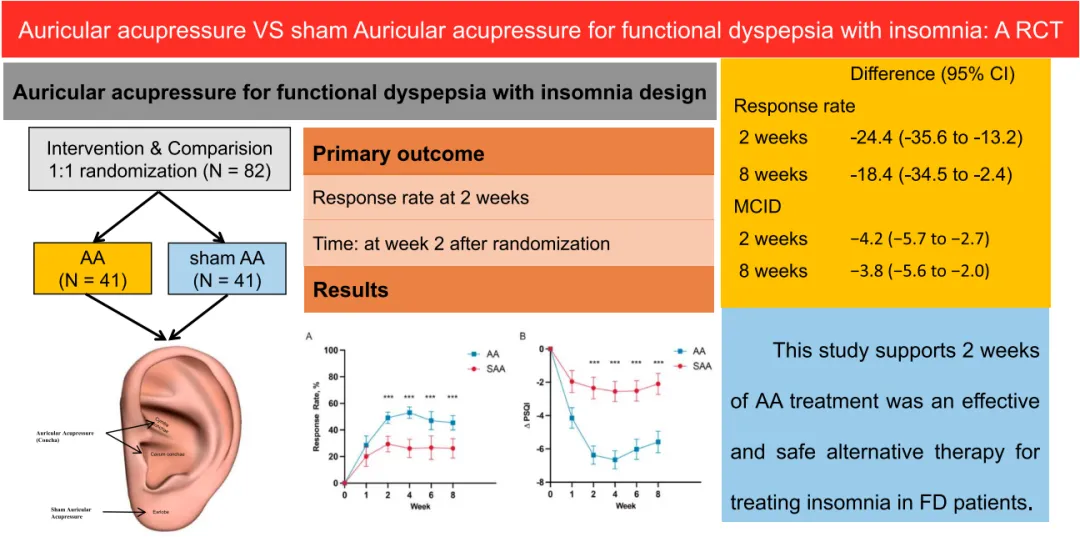
近期,浙江中医药大学附属第一医院,浙江省中医院吴建浓教授团队开展了一项临床试验,试验成果发表在《The American Journal of Gastroenterology》期刊(医学一区,IF = 8.1)上。
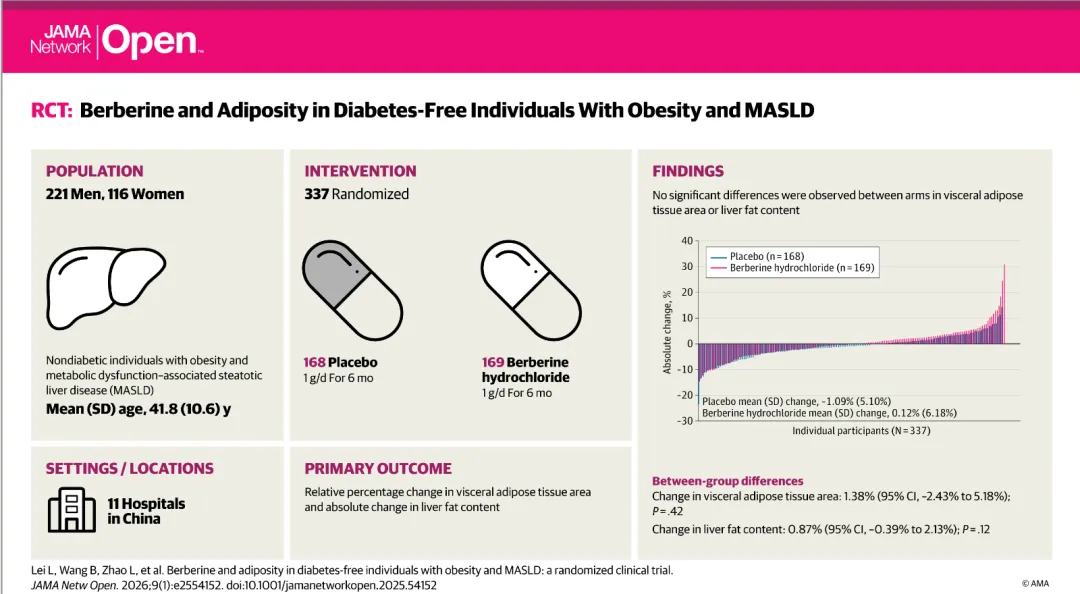
2026年1月16日,由中国医学科学院阜外医院李静研究员和张海波副研究员领衔,开展了一项针对无糖尿病且患肥胖和代谢功能障碍相关脂肪肝病(MASLD)患者的随机、双盲、安慰剂对照临床试验。
-JxQI.jfif)
2025年9月9日,北京大学公共卫生学院流行病学与生物统计学系孙凤教授团队在《Phytomedicine》(医学一区,IF=8.3)发表了一项回顾性真实世界研究。

穴位按压作为中医传统疗法的一种,具有独特的优势。通过对特定穴位的按压刺激,可以调和气血、疏通经络,从而达到缓解疼痛、改善关节功能的目的。
在现实中,疾病的发生和发展通常是由复杂的、相互依赖的多个变量相互作用的结果。病人往往有多种共病,指标都是动态变化的。 比如我们要如何理解血糖、血压、胆固醇这三者在一个糖尿病患者群体中5年内的变化关系?这些指标之间是如何相互关联、共同演变的?


中介分析到底该怎么做?最近看到一篇武汉教育部青少年网络心理学与行为重点实验室学者在二区SCI发了一篇论文,做了一个纵向中介模型,我们一起看看!

今天解读一篇2025年11月20日发表在医学顶刊柳叶刀《Lancet》主刊(医学一区,IF=88.5)上的一篇临床试验论文。这项临床试验研究设计很特别,采用2×2析因设计,且不是常规的平行组设计,而是分两阶段实施的序列随机化研究,郑老师团队统计师来详细说说!

自从风暴统计平台上线,临床预测模型功能就已经开放免费使用了,零代码解决了很多基础比较差的朋友的难题。 近期,很多朋友在交流群里问,什么时候可以上线LASSO回归方法?
-TxHv.jfif)
2025年9月24日,浙江大学何威副教授研究团队在医学顶刊《BMJ》杂志发表最新研究。分析超 43 万名女性,最长随访至 25 年的数据,结论直击核心:首次乳腺癌筛查缺席的女性,后来更常因为症状才被发现、分期更晚、25 年乳腺癌死亡风险显著更高。
-OEat.jfif)
你是否曾遇到过如下情况:明明做了回归分析,但模型结果怎么都解释不通?数据明显右偏态,不满足线性模型假设?数据波动范围太大,模型无法捕捉规律?来看看这篇文章
顶级医学期刊BMJ在2023年底陆续发布了三篇临床预测模型评估指南,为研究人员开展临床预测模型研究提供了权威的参考资料。本系列推文的前两篇围绕BMJ指南的内容详细介绍了模型内部验证和外部验证方法。而本推文是模型评估系列文章的最后一篇,将结合案例针对性地介绍如何计算外部验证所需的样本量。

今天,给大家介绍的是NHANES Online平台可分析的第439个NHANES 新型肺功能异常表型类指标-----保存比率受损肺功能测试(PRISm)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。
今天,给大家介绍的是NHANES Online平台可分析的第438个NHANES 心肾标志物类指标-----尿素氮肌酐比值(BUN_Cr)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。值得一提的是,该指标目前发文仅1篇!!!
今天,给大家介绍的是NHANES Online平台可分析的第436个NHANES 体脂肪指数类指标-----锥度指数(C-index)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。

今天,为大家介绍的是CHARLS的高分选题——早期经历饥荒。 在CHARLS的公开研究中,饥荒暴露指标已被广泛应用于抑郁症状、慢性病共病、2型糖尿病、代谢综合征及认知功能等健康结局的关联分析。目前该领域累计发文已达38篇。
今天,给大家介绍的是NHANES Online平台可分析的第439个NHANES 新型肺功能异常表型类指标-----保存比率受损肺功能测试(PRISm)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。
今天,给大家介绍的是NHANES Online平台可分析的第438个NHANES 心肾标志物类指标-----尿素氮肌酐比值(BUN_Cr)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。值得一提的是,该指标目前发文仅1篇!!!
今天,给大家介绍的是NHANES Online平台可分析的第436个NHANES 体脂肪指数类指标-----锥度指数(C-index)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。

谁说公共数据库不能发高分文章?这篇2026年首个登上JAMA顶刊的文章以NHANES数据为自我报告的BMI进行纠偏,估算并预测了美国不同群体的肥胖流行率。

今天这篇文章真的不得了了! 多个中国大佬团队依托GBD 2021+GLOBOCAN 2022两大数据库,瞄准“儿童癌症”这一罕见病领域,发表开年首篇CA!(这本被视为“肿瘤学圣经”的期刊其含金量不必多言) 如此权威的高分思路,一起来学习下吧。 如果你也想用GBD数据冲击高分SCI,欢迎选择郑老师团队的GBD数据库挖掘课程——从选题、数据提取到文章复现,告别科研焦虑!

慢性呼吸系统疾病,包括慢性阻塞性肺疾病(COPD)、哮喘、尘肺病、间质性肺病(ILD)及肺结节病,是全球范围内导致死亡和疾病的主要原因。尽管新冠疫情影响了急性呼吸系统健康,但其对慢性呼吸系统疾病的影响仍不明确。

贫血作为全球重大健康问题之一,先前研究显示,贫血负担在低社会经济发展中地区更高,发展中国家贫血相关残疾占总数的 89%。2021 年,中国贫血患者人数达到 1.36 亿,占全球贫血病例近 7.0%,表明中国贫血负担不容忽视。
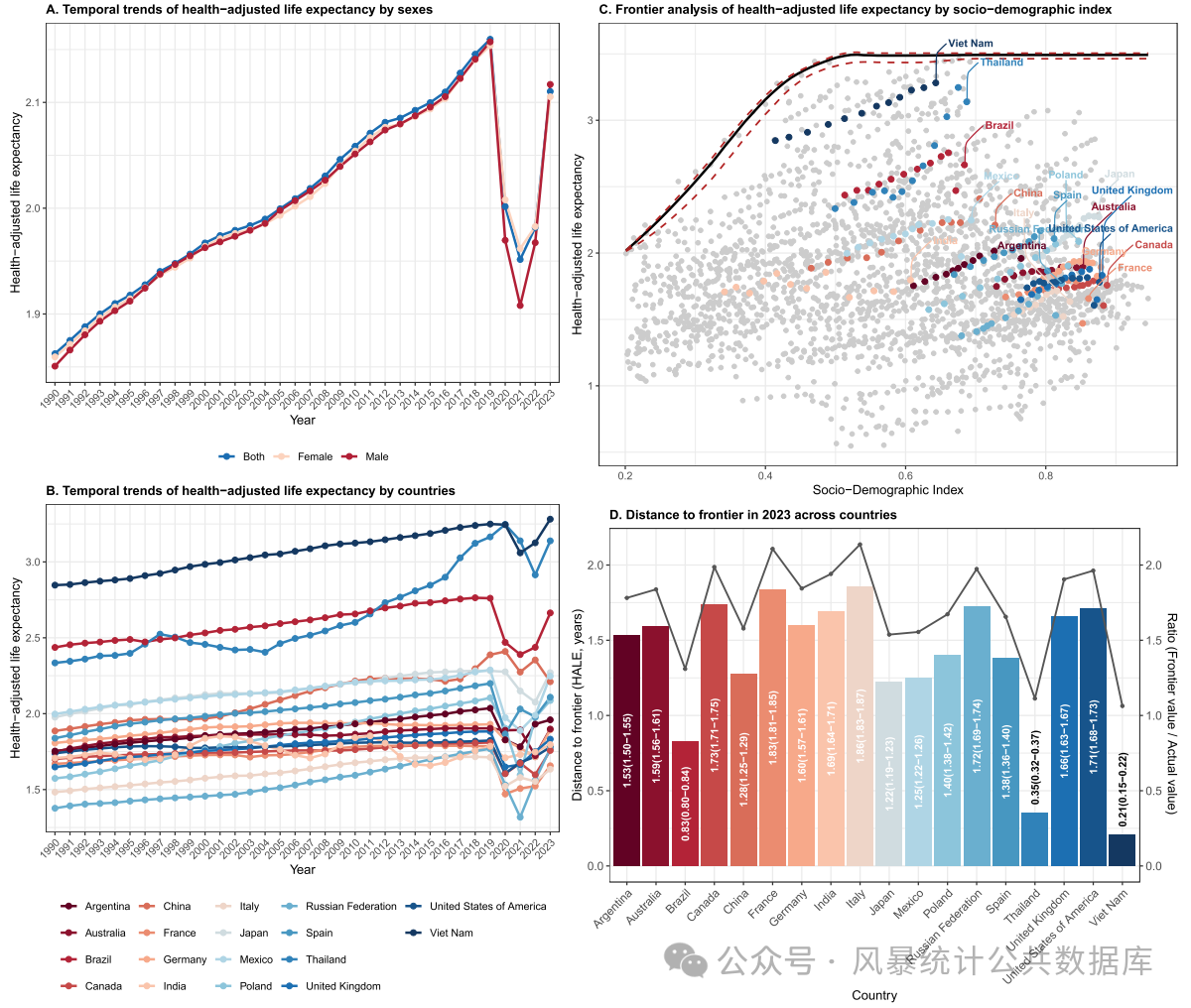
全球人口正快速老龄化,高龄老人(95岁及以上)群体规模迅速扩大。然而,寿命延长并不必然意味着健康状况的改善。尽管遗传和环境因素共同影响寿命,但已有证据表明,针对性干预可显著提高活到百岁的可能性。
今天,为大家介绍的是CHARLS的高分选题——早期经历饥荒。 在CHARLS的公开研究中,饥荒暴露指标已被广泛应用于抑郁症状、慢性病共病、2型糖尿病、代谢综合征及认知功能等健康结局的关联分析。目前该领域累计发文已达38篇。
今天,为大家介绍的是CHARLS又一个虚弱指标的算法,该算法是根据Fried物理衰弱表型(Physical Frailty Phenotype, PFP)来定义的。目前用该量表计算的虚弱指数,在CHARLS领域仅发文15篇!
2025年11月,亚洲肌少症工作组(AWGS)发布了肌少症2025年的最新共识。该共识立足全生命周期管理理念,在与国际倡议保持协同的基础上,为亚太地区提供了本土化临床指南。
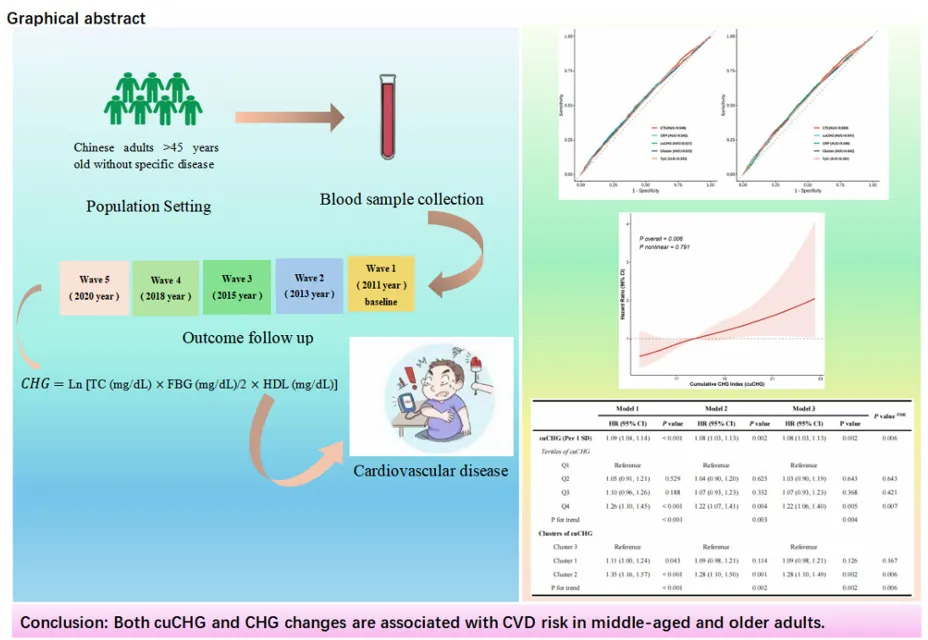
CHARLS数据库又一稀有高分选题来袭!深圳大学学者借新指标cuCHG以及动态轨迹分析,直接斩获两篇一区Top,足以证明该指标和分析思路的优秀!
-wDZi.jfif)
2023年12月29日,一篇题为Causal Effects of Basal Metabolic Rate on Cardiovascular Disease: A Bidirectional Mendelian Randomization Study的孟德尔随机化研究论文发表于《Journal of the American Heart Association》,作者为中国学者,文章属于中科院医学一区,IF=5.4。
-myNU.jfif)
本文结合横断面研究和孟德尔随机化来探索脂质生物标志物与骨关节炎(OA)之间的关系。利用NHANES数据库筛选有血脂标志物、OA及相关协变量的参与者,共筛选了3706名参与者。
-ZTbx.jfif)
2024年2月,华中科技大学公共卫生学院学者在《Metabolism-clinical and Experimental》(一区,IF=9.8)发表题为:"Nonlinear relationship between high-density lipoprotein cholesterol and cardiovascular disease: an observational and Mendelian randomization analysis" 的研究论文。

2024年1月,中国学者在《Eur J Epidemiol》(一区,IF=13.6)发表题为:"Vitamin D and human health: evidence from Mendelian randomization studies" 的研究论文。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式


-kfnp.png)

-wqtd.png)

