
引用(作者在文献中承认先前来源的方式)是衡量一篇论文影响力的一个指标。 但被引用次数最多的论文通常并不是最著名的科学发现。相反,这些作品倾向于描述科学方法或软件,科学家们

老郑看到一篇仅有一位作者的独著SCI论文,不禁想和诸位分享一下! 中国医科大学公共卫生学院学者在期刊《Globalization And Health》
2025年3月31日,中国学者在期刊《Cancer Letters》(医学一区,IF=9.1)上发表了一篇文章,推出开源平台SurvivalML</
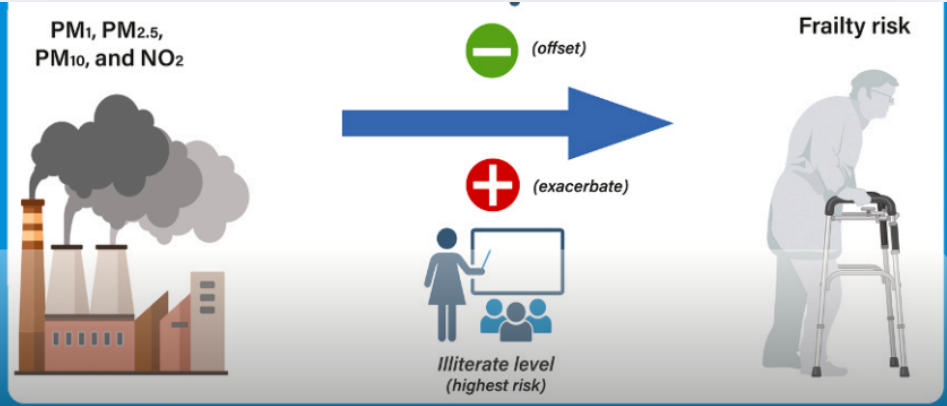
随着人口老龄化趋势日益加剧,虚弱已经成为影响中老年人群健康的重要挑战。它不仅增加了住院、死亡风险,还加重了医疗系统的负担。而在众多可能影响虚弱的因素中,“空气污染”近


目前,糖尿病正以惊人的速度席卷全球。然而,比高患病率更严峻的是其与虚弱的“致命叠加”,大大增加了患者的死亡风险!既往研究多局限于单一队列或高质量荟萃分析,且多数研究未


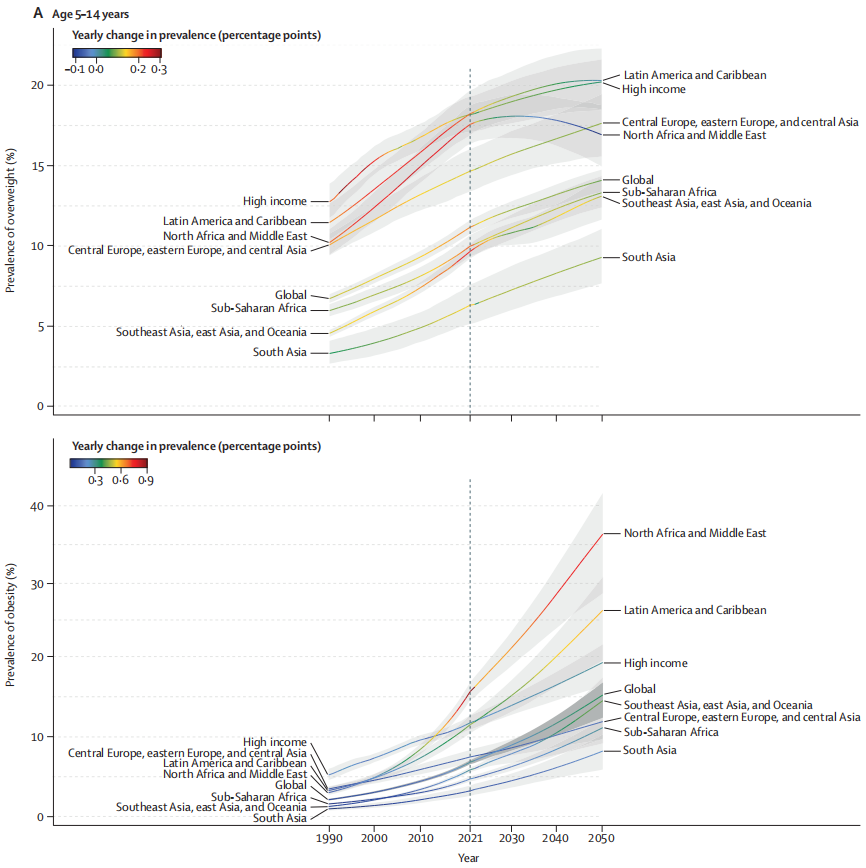
随着人口老龄化与代谢性疾病激增,我国中风负担持续加重。在代谢异常与肥胖交织的现代健康危机下,两个关键指标——反映胰岛素抵抗的甘油三酯葡萄糖(TyG)指数和衡量内脏脂肪的体圆指数(BRI),对中风的联合作用尚未充分研究。

2025年4月23日,Nature子刊《Nature Medicine》(医学一区,IF=58.7)连发两篇外国学者对DeepSeek大型语言模型在临床应用的基准评价文章!
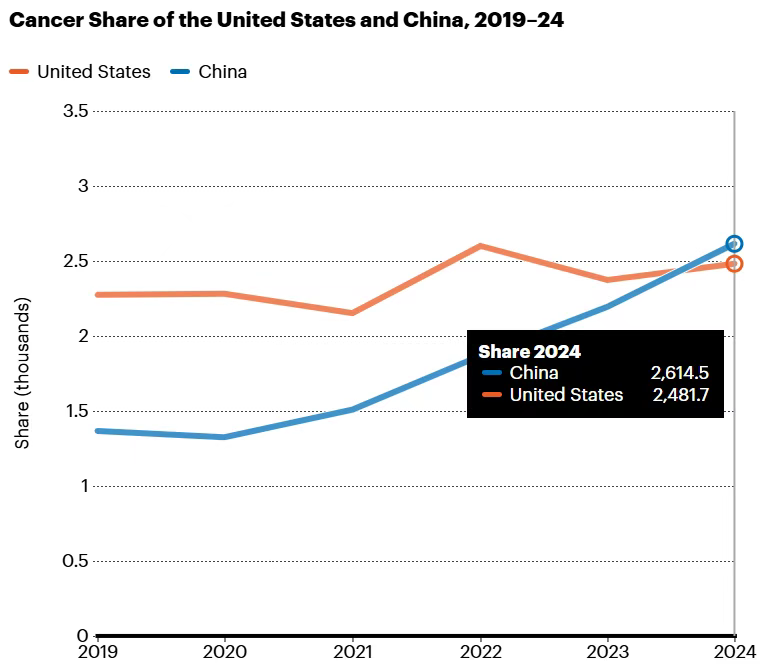
2025年4月23日,Nature发布癌症研究领域Nature Index,中国在癌症相关研究方面排名第一,产出大幅增长。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

