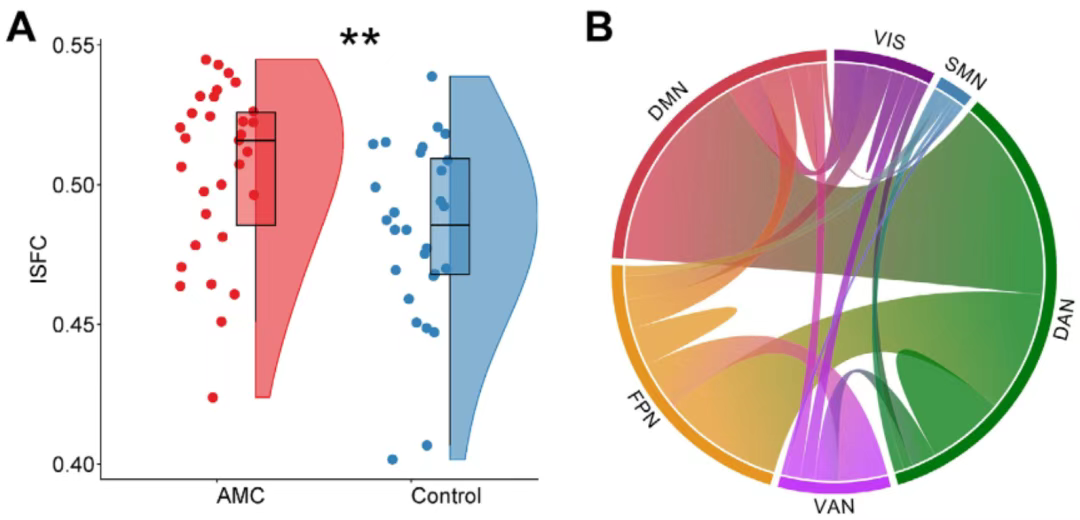
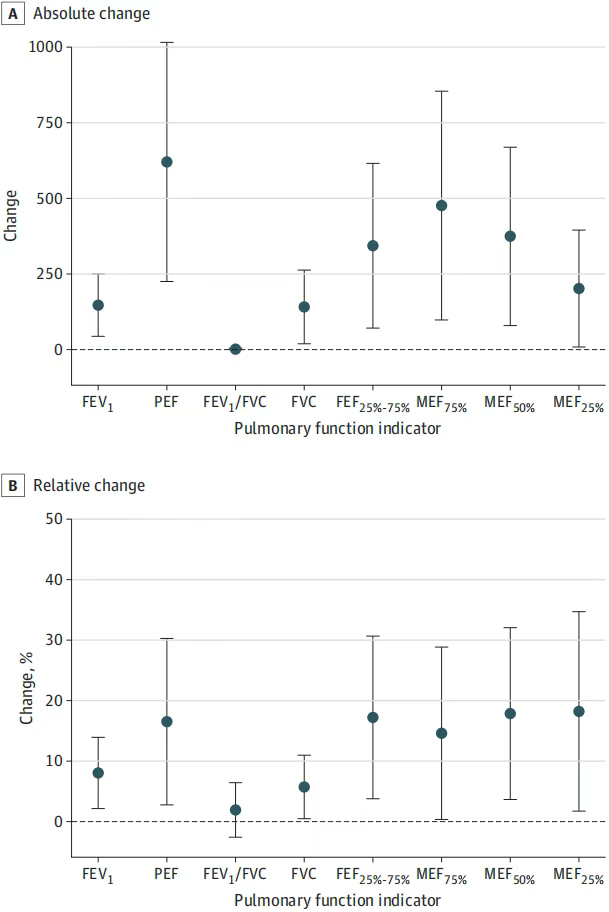
2025年7月11日,由浙江大学陈飞燕教授团队领衔,与华东师范大学、香港浸会大学、德国奥尔登堡大学联合开展的研究发表在期刊《Advanced Science》(IF=14.1)。 这项长达五年的科学研究发现,珠心算训练
常规机器学习分析的文章大家都看了不少了,今天给大家分享一篇基于4种不同中国青少年受欺凌的受害者轨迹,使用常见的随机森林(RF)法构建预测模型。 先来看看本文的研究设计吧: 1.数据收集与处理
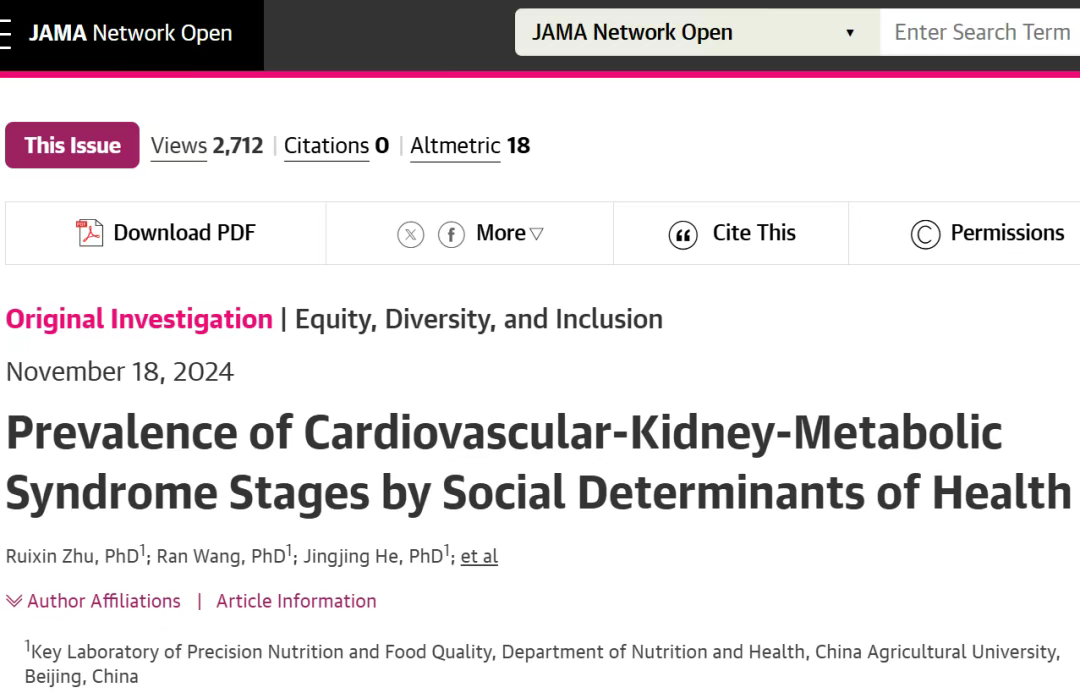
2023年10月,美国心脏病协会(AHA)新定义了心血管-肾脏-代谢综合征(CKM),并按照疾病的风险因素,将其分为5期。 先前有研究者用NHANES数据库,探讨2011年至2020年间心血管、肾脏和代谢(CKM)综合征分期患病率及其随时间的变化,发表了JAMA正刊。

之前我们解读过两篇关于目标仿真试验(老郑的俗称:模拟RCT)的文章,老郑的公益直播也讲解过什么是目标仿真试验,不清楚这个概念的可以看下面的文章简单回顾一下。

医学统计学是医学论文中不可或缺的组成部分,也是从事科学研究和临床工作的必备工具。 然而,一项Meta分析中提到我国临床医务人员对医学统计学理论和统计软件的认知率分别为3
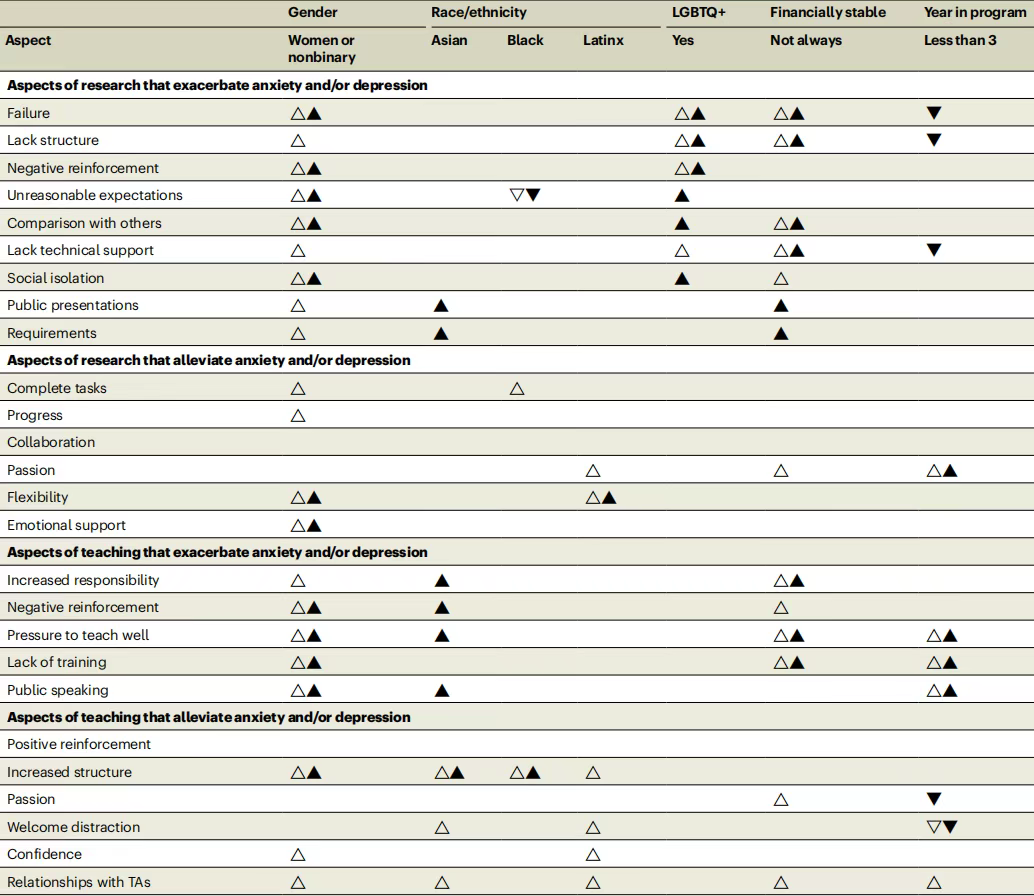
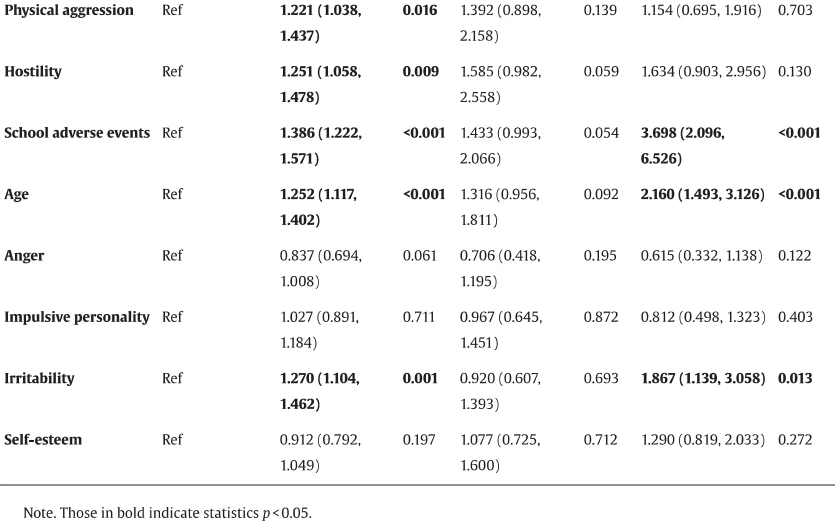
《自然》子刊实锤:“导师 push”,例如过度严厉的批评甚至责骂,以及对学生抱有不切实际的期望对研究生的心理健康伤害最大! 近年来,越来越多现实案例告诉我们,研究生的心理问题不容小觑。据报道,35.5%的研究生有抑郁倾向,超一半研究生可能存在焦虑问题。而且,博士生的抑郁、焦虑平均水平显著高于硕士生。
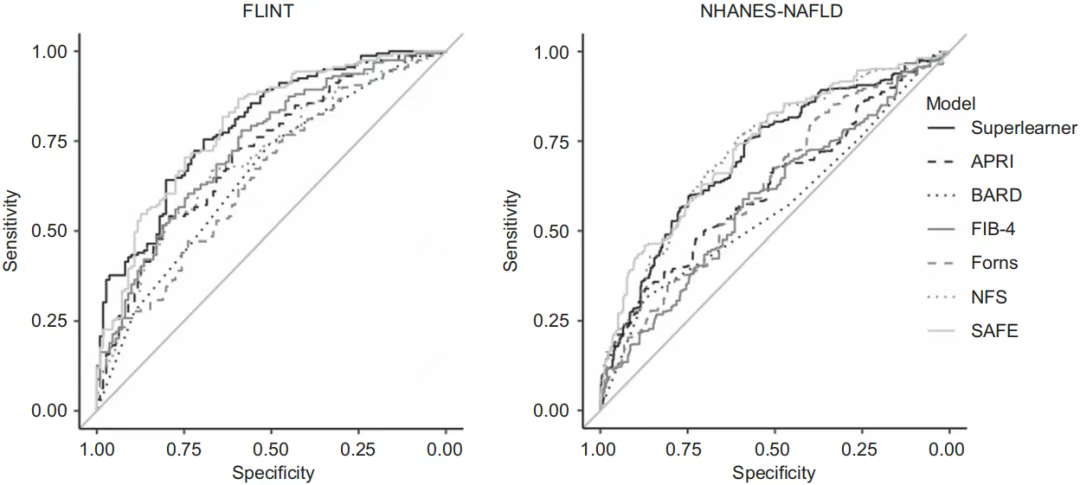
众所周知,回归模型是构建临床预测模型的主力。事实上,过去十年里开发的用于预测肝纤维化的非侵入性的工具,大多都依赖于逻辑回归模型。 尽管机器学习方法功能强大,但研究者们无法准确把握哪种机器学习法
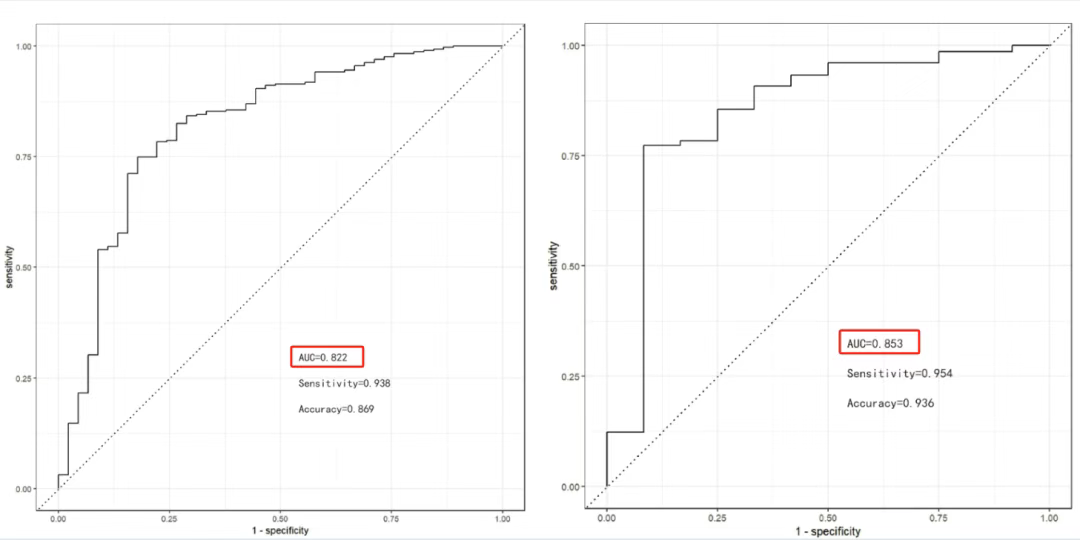
剖宫产子宫瘢痕异位妊娠(CSEP)是剖宫产术后妊娠的一种潜在致命的并发症,可能导致孕妇大出血或死亡。手术中的出血量直接影响手术的成功率。 近年来,基于电子病历(EMR)数据构建的机器学习(ML)预测模型研究日益增多。本研究团队开发的最佳预测模型已被集成到一个网络应用程序中,使临床医生无需掌握R语言或编程技能即可预测CSEP患者的术中风险。 2024年12月,中国学者在医学顶级期刊Lancet子刊《eClinicalMedicine》(医学一区top,IF=9.6)发表了一篇题为:“Risk of intraoperative hemorrhage during cesarean scar ectopic pregnancy surgery: development and validation of an interpretable machine learning prediction model”的研究论文。 在该项研究中,研究团队使用四种方法确定模型的预测因子,并使用八种机器学习法构建预测模型。不同于我们之前介绍的SHAP法,本研究使用"iBreakDown"包对模型进行可视化。
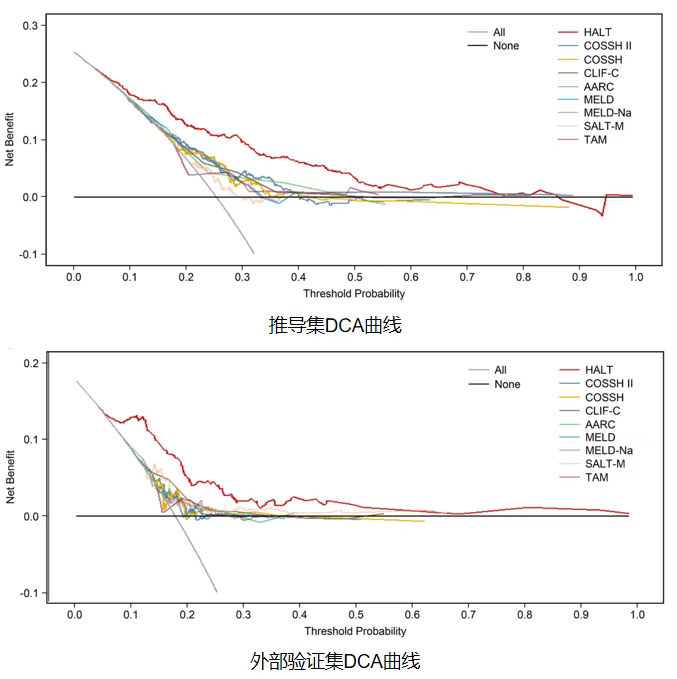
2025年7月17日,浙江大学附属第一医院凌琪教授团队基于全国多中心队列研究,开发并验证一种新型预后模型,用于预测急性加重型乙型肝炎肝功能衰竭(HBV-ACLF)患者术后 1 年死亡率,发表在医学顶刊柳叶刀子刊《eBioMedicine》(医学一区top,IF=10.8)。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式




