
2025年11月,亚洲肌少症工作组(AWGS)发布了肌少症2025年的最新共识。该共识立足全生命周期管理理念,在与国际倡议保持协同的基础上,为亚太地区提供了本土化临床指南。
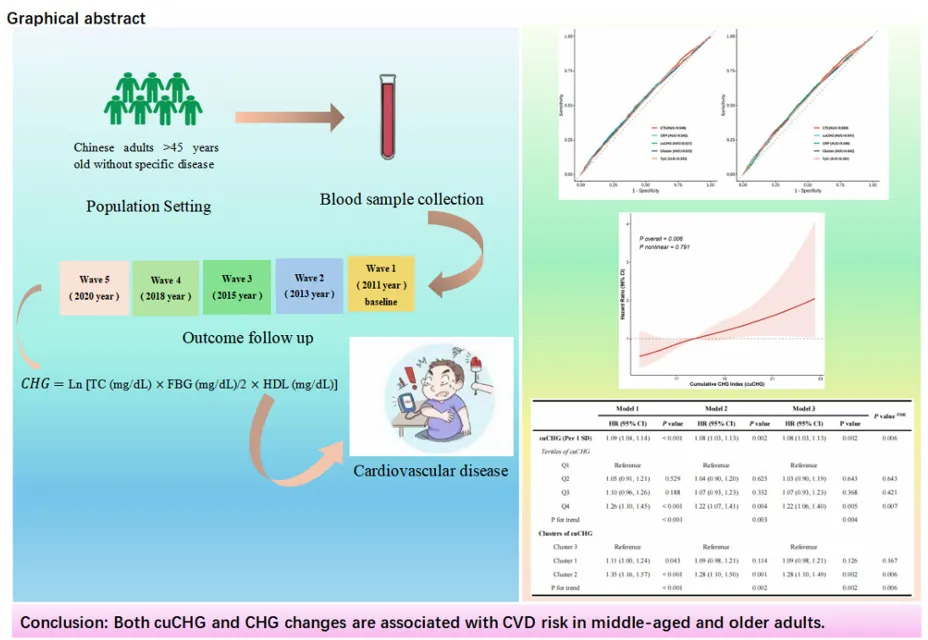
CHARLS数据库又一稀有高分选题来袭!深圳大学学者借新指标cuCHG以及动态轨迹分析,直接斩获两篇一区Top,足以证明该指标和分析思路的优秀!
今天,为大家介绍的是CHARLS近期热度飙升的稀有指标——甘油三酯-总胆固醇-体重指数(TCBI)。该指标目前在CHARLS领域仅发文5篇!
第一反应就是,这个指标很适合CHARLS研究,不过原定义中很多变量CHARLS没有,因此我们计算了短体能测评量表SPPB得分,该指标可以用来替代进行老年人运动功能测试!!且目前仅发文8篇!!

今天,给大家介绍的是NHANES Online平台可分析的第424个NHANES 高分综合指标-----社会经济地位(SES)。同时,还分享了高分文献是如何描述该指标的,以供大家参考。

近日,由首都医科大学护理学院岳鹏教授团队领衔、发表于 《JAMA Network Open》(IF 9.7)的一项定性研究,深入北京4家安宁疗护机构,访谈了39位患者、家属及专业人员,首次揭示了关于中国居家临终关怀质量评价体系。

2026年3月21日,首都医科大学附属北京天坛医院王拥军院士、李子孝教授团队在医学顶刊《BMJ》(医学一区top,IF=42.7)发表了一项重磅研究。
今天,为大家介绍的是CHARLS稀有指标——改良心脏代谢指数(MCMI),其在CHARLS仅发文2篇!

最近在医学顶刊Lancet子刊《Lancet Digital Health》(医学一区top,IF=24.1)看到一篇非常有意思的研究论文。 该研究来自一个庞大的国际多中心团队,为精准预测“T+A”免疫联合疗法(阿替利珠单抗+贝伐珠单抗)对晚期肝细胞癌患者的疗效,结合了13种特征筛选方法与7种机器学习算法构建预测模型。
近期,山东大学齐鲁医院张运院士、张澄教授团队领衔开展了一项随机对照临床试验(TXL-CAP 研究),研究成果发表在Nature子刊《Signal Transduction and Targeted Therapy》期刊(医学一区,IF = 52.7)上。
Zstats交流群
联系助教
请输入助教告诉您的积分券
如果不填写积分券,将直接使用当前余额支付
请稍候,正在为您生成支付订单
请使用扫描二维码完成支付
二维码获取失败
支付二维码获取失败,请点击重新获取
请稍候,正在为您完成支付
正在使用积分券兑换,然后完成支付 正在使用当前余额完成支付
您的订单已支付完成,页面将在 秒后自动关闭
支付过程中出现错误,请重新选择支付方式

