2025年2月24日,北京大学肿瘤医院沈琳教授团队III期临床试验-GEMSTONE-303研究成果在医学顶刊《JAMA》(医学一区top,IF=63.1)
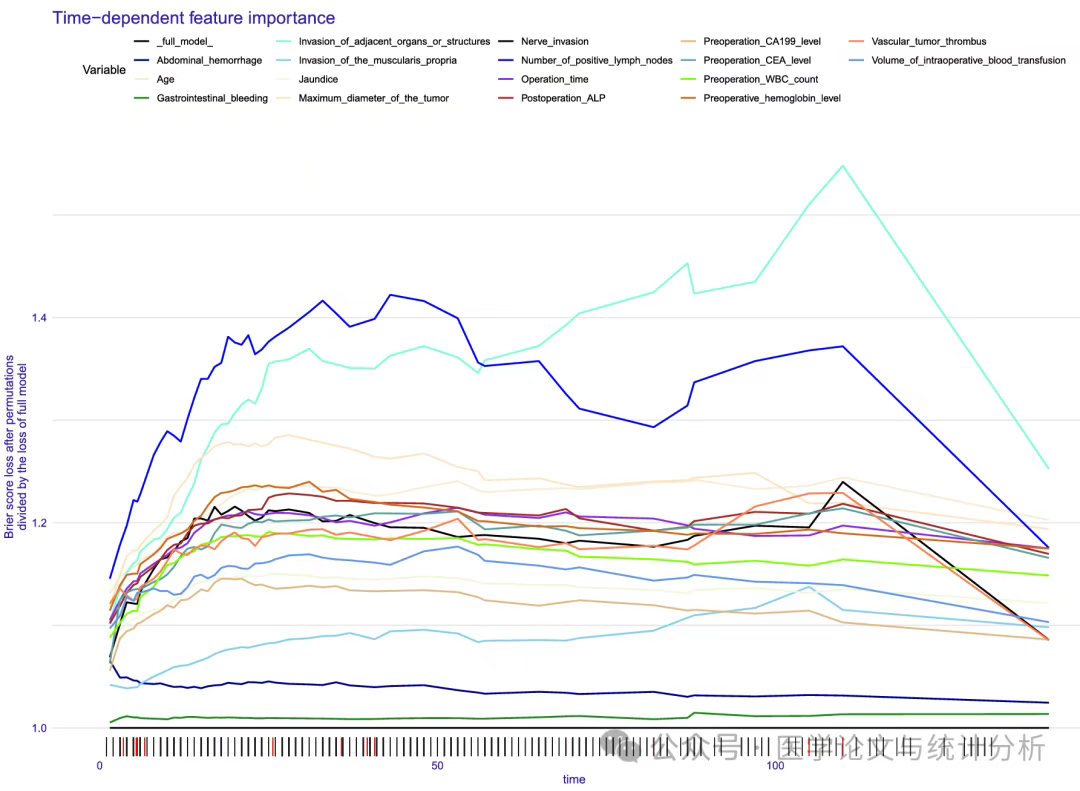
老郑看到一篇文章,机器学习建模建了100个,挺有意思的,是实力?还是内卷?我们一起看看! 这篇文章是中国学者发表在中科院一区,影响因子7.0的杂志《BMC Medicine》
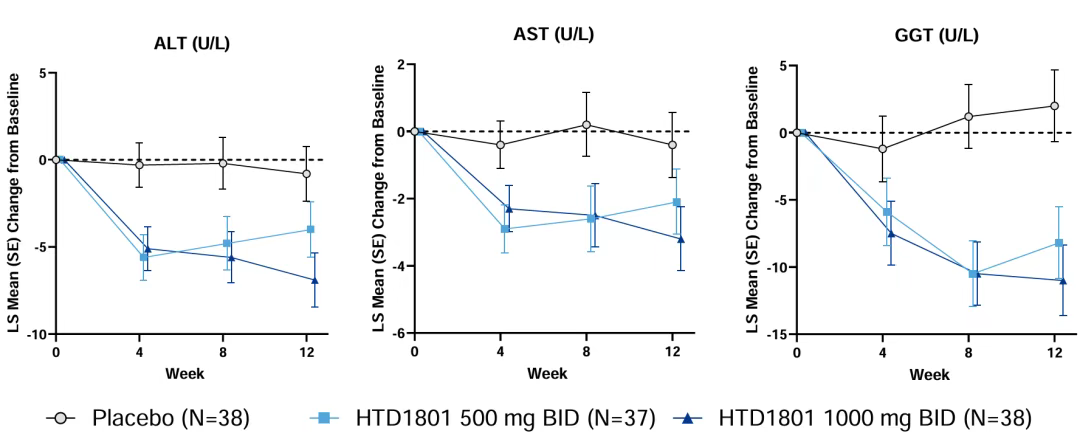
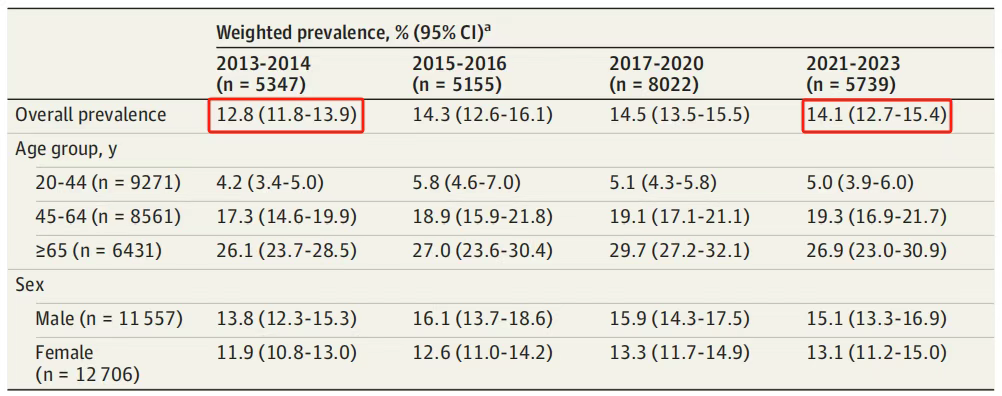
近日,北京大学学者团队在JAMA子刊《JAMA Network Open》(医学一区top,IF=10.5)发表了一项仅每组约38例患者的2型糖尿病创新药临床试验成果,小样本研究如何征服顶刊?我们一起看看! 这篇文章题为:
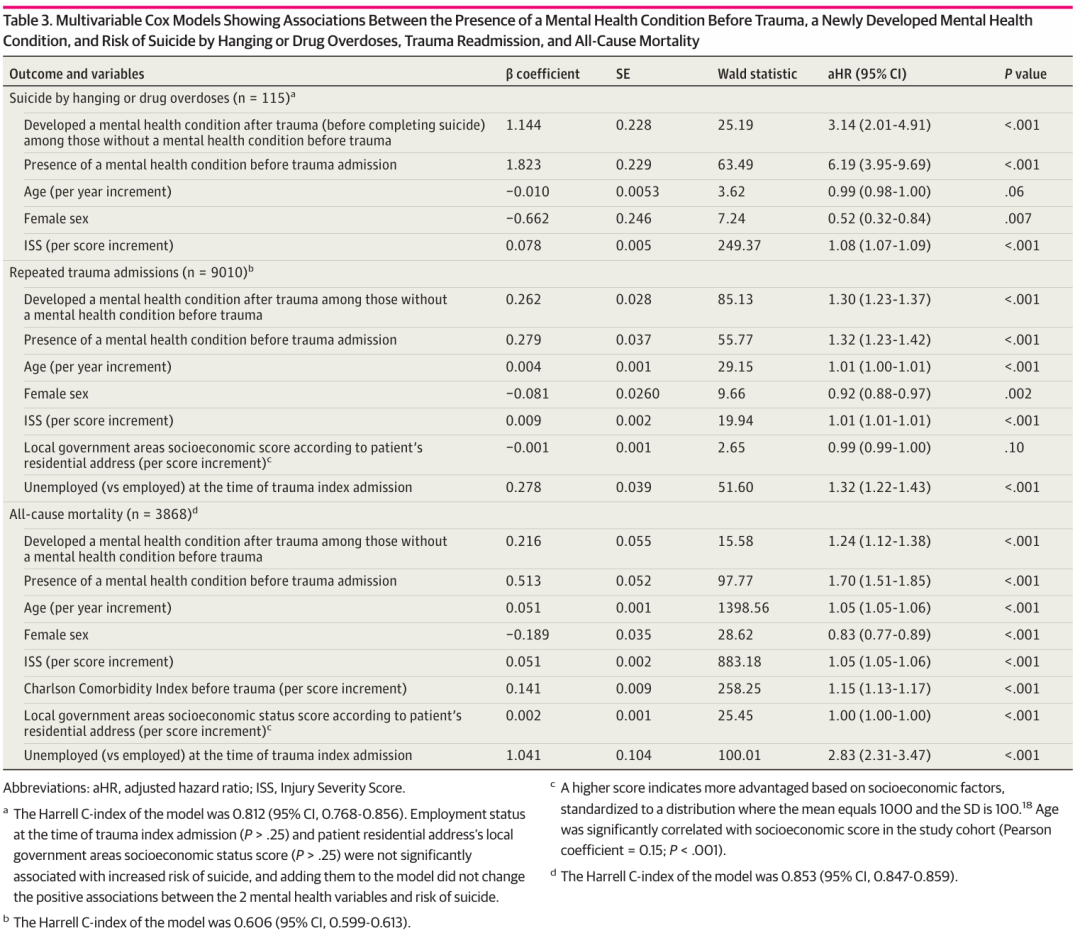
回归分析是观察性研究中很重要的手段,通过模型调整,其目的是探讨多因素情况下,各个因素的独立效应。 那么,困惑诸多分析者的问题是,调整模型,也就是多因素回归分析,只能纳入单因素P<0.05的变量吗? 这个问题其实郑老师很早就回答过了,筛选自变量,最简单的方式、也最常见的方式是“先单因素后多因素法”,
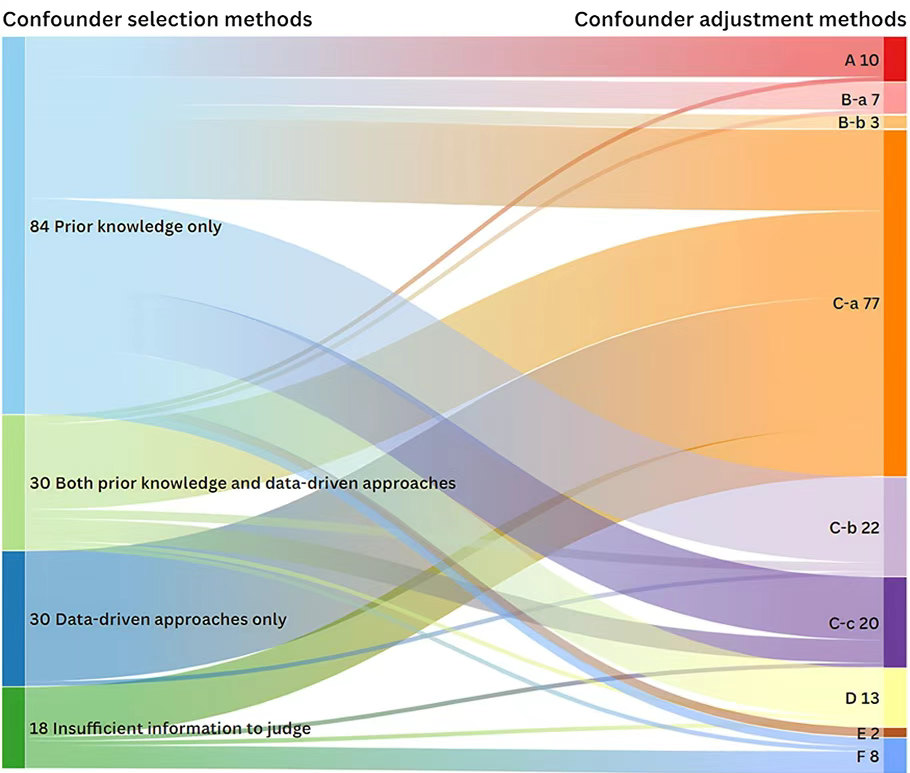
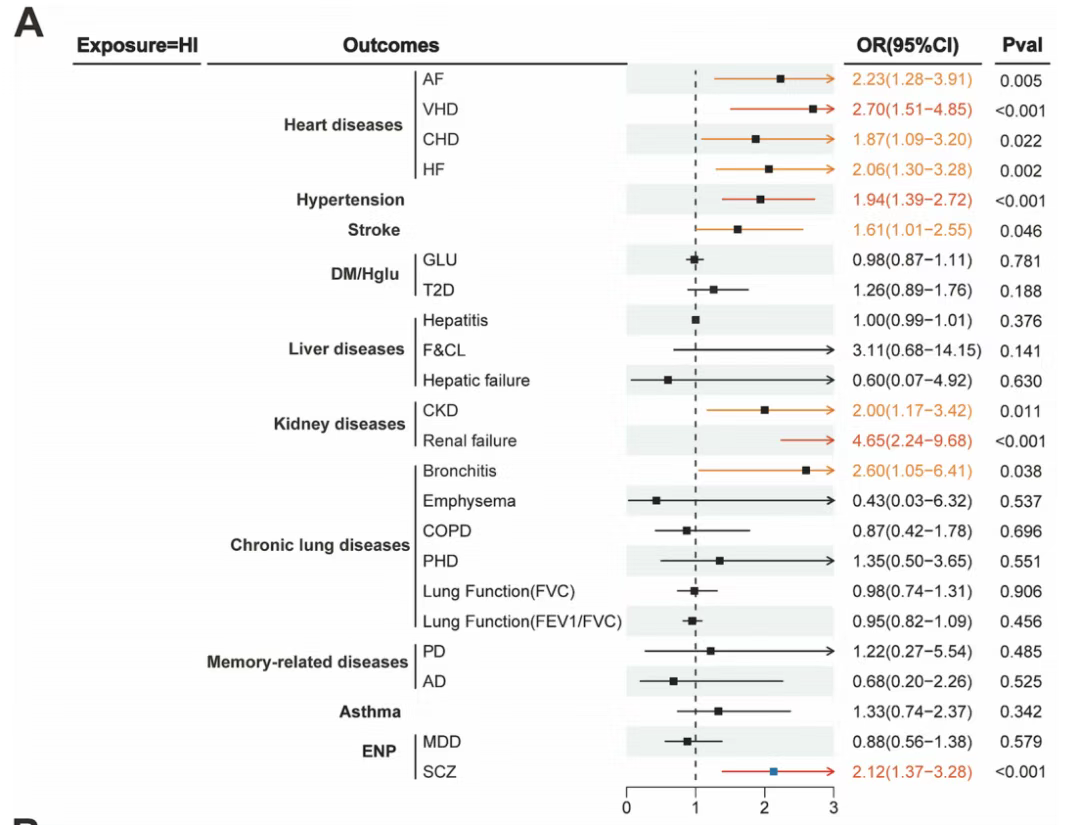
在医学观察性研究中,混杂因素调整是确保因果推断准确性的核心步骤。然而,当研究涉及多个风险因素时(如心血管疾病、糖尿病、痴呆等),混杂因素的调整方法是否合适往往被忽视! 但是,不恰当的混杂因素调整可能导致效应大小的低估、高估甚至反转。 2025年3月5日,中南大学湘雅公共卫生学院学者团队在《BMC M
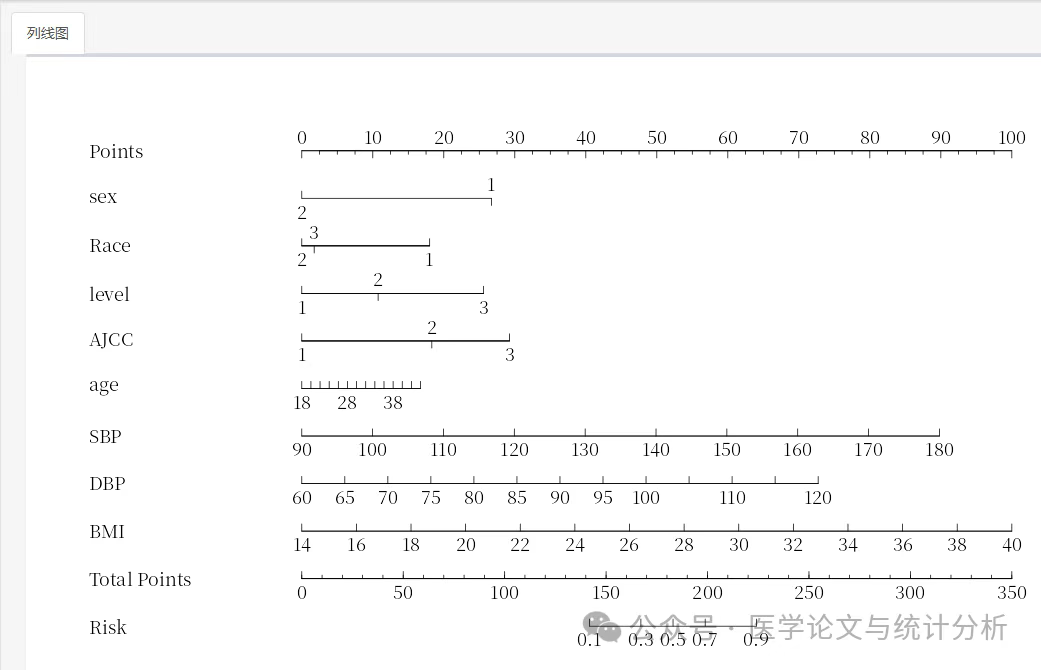

很多时候,开展临床、护理研究,通过一项调查或者最终研究,我们当然你希望去探讨因果关系。但是,很多时候,流行病学研究不仅仅是因果关系研究,也可能是描述性研究或者预测研究。 在这种情况下,如果我们开展了一箱基于回归分析的研究,通过分层或者多变量回归控制了“混杂”,那就可以说是“独立的影响因素”,视为具有
-LwLc.png)
算法狂欢的时代,为何这篇"返璞归真"的研究能登顶柳叶刀子刊? 老郑看到这样一篇文章,在机器学习横扫科研圈的今天,仅用Logistic回归构建预测模型,发表在期刊
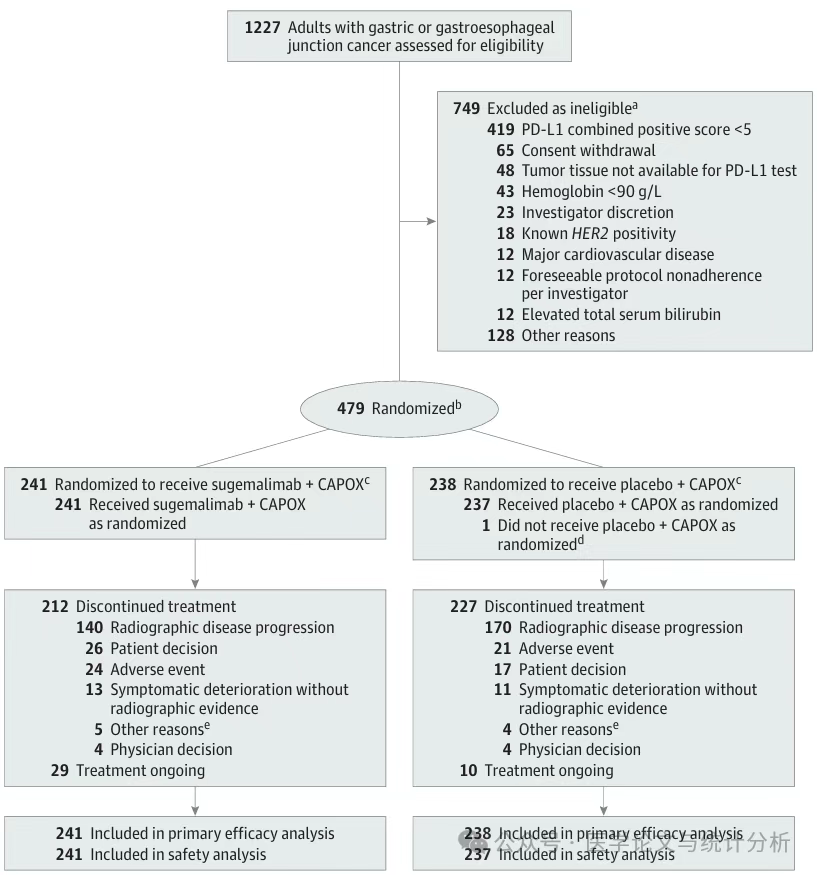
2025年3月13日,中山大学肿瘤防治中心孙颖教授团队III期临床试验-DIPPER研究成果在医学顶刊《JAMA》(医学一区top,IF=63.1)
-kCZo.png)
可能是导师太笨,或者自己学生太笨,培养了半天,终于让我的研究生学会写R语言函数了! 喜大泪奔! 任务也很简单,对成组两样本t检验模块,写出R语言函数,并且形成shiny在线分析模块。 <